
Key Results
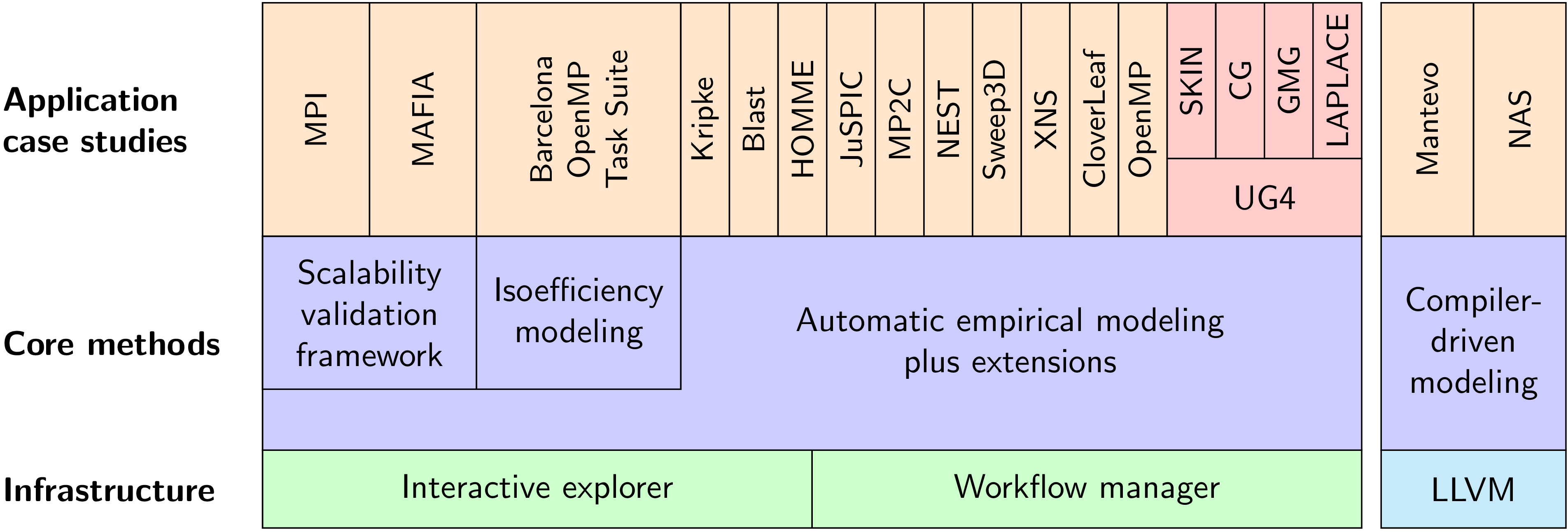 |
Our main accomplishments, which are illustrated in Figure 1, can be summarized as follows:
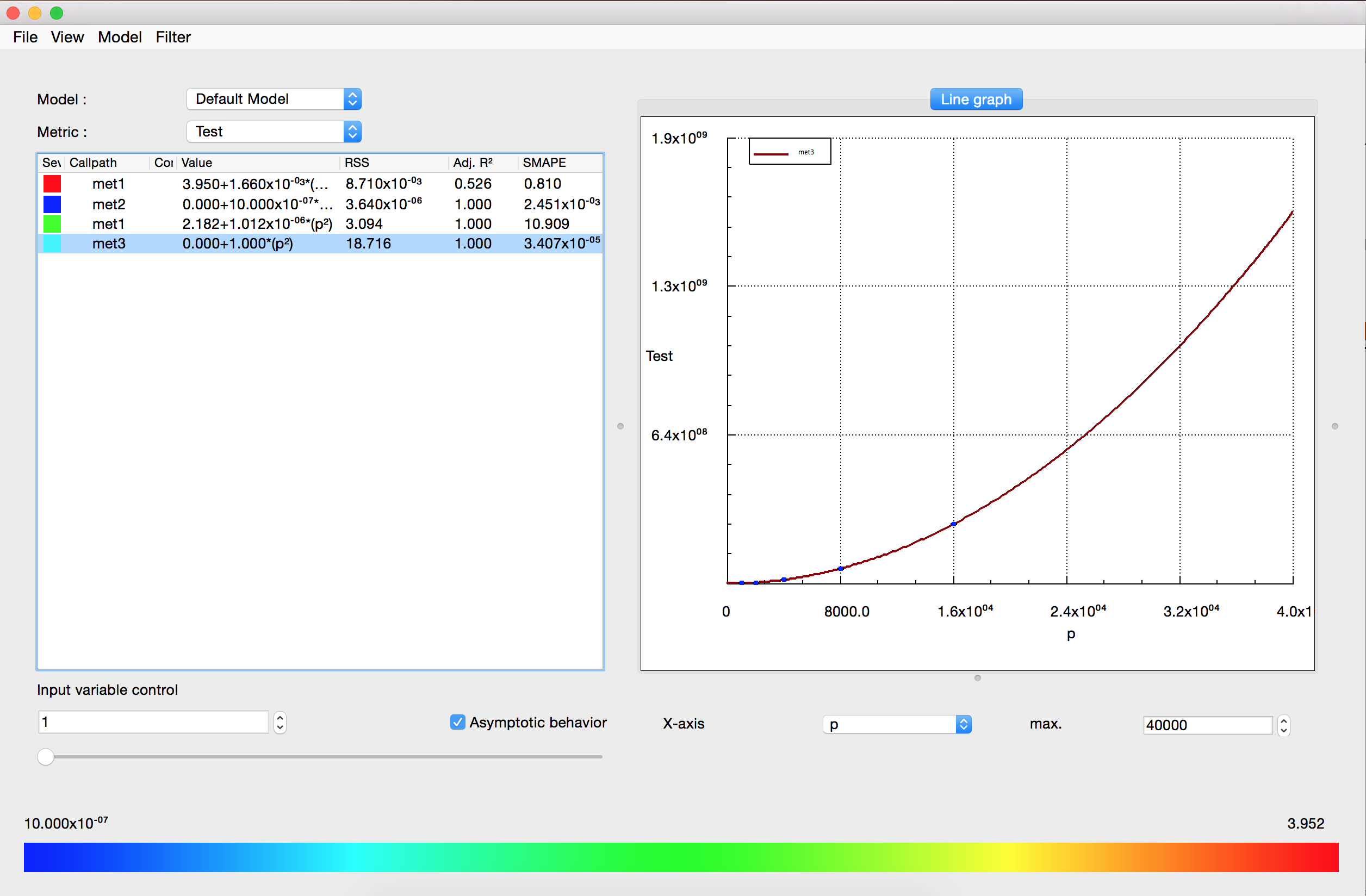
- A method to automatically generate scaling models of applications from a limited set of profile measurements, which allows the quick identification of scalability bugs even in very complex codes with thousands of functions [DOI, PDF]. The method was integrated into the production-level performance-analysis tool Scalasca (Figure 2).
- Numerous application case studies in which we either confirm earlier studies with hand-crafted performance models or discover the existence of previously unknown scalability bottlenecks. In particular, we conducted a detailed analysis of UG4, an unstructured-grid package developed by one of our partners, and confirmed a previously known issue of the CG method as well as identified a previously unknown scalability issue in an initialization routine [DOI, PDF].
- A scalability analysis of several state-of-the-art OpenMP implementations, in which we highlight scalability limitations in some of them [DOI, PDF].
- A scalability test framework that combines our base method with performance expectations to systematically validate the scalability of libraries [DOI, PDF]. Using this framework, we conducted an analysis of several state-of-the-art MPI libraries, in which we identify scalability issues in some of them. Moreover, an analysis of MAFIA, a subspace clustering package, demonstrates the frameworks ability to model algorithmic parameters beyond pure scalability considerations.
- Static analysis techniques to count the number of loop iterations in various applications [DOI, PDF]. The analysis can model the number of iterations for arbitrary affine loop nests, and potential parallelism in programs symbolically.
- Heuristics to quickly generate performance models for more than one parameter in spite of a significantly enlarged search space [DOI, PDF].
- An empirical method to determine the isoefficiency function of task-based applications. We compare realistic and contention-free isoefficiency to assess the effect of limited shared resources such as memory bandwidth. Moreover, we calculate an upper-bound on efficiency to uncover structural optimization potential in the task graph[DOI, PDF].
- An alternative approach to the generation of performance models that forgoes preconfigured search spaces, iteratively refining performance models while avoiding overfitting. This improves accuracy and streamlines the modeling process [DOI, PDF].
- An extension of the modeling process that recognizes when the underlying measurements represent multiple behaviors and segments the data accordingly [DOI, PDF].
As shown in Figure 1, the core methods we developed include both an automatic empirical method and compiler-driven methods. The empirical method rests on infrastructure components developed by project partners, the compiler-driven methods leverage LLVM, an external open-source compiler infrastructure. The empirical method was later extended to also allow scalability validation of codes with known theoretical expectations. Both sets of methods have been successfully applied in a number of application studies. The unstructured-grid package UG4 (highlighted) is developed by one of the project partners, all other test cases were external to the project team.
 |
